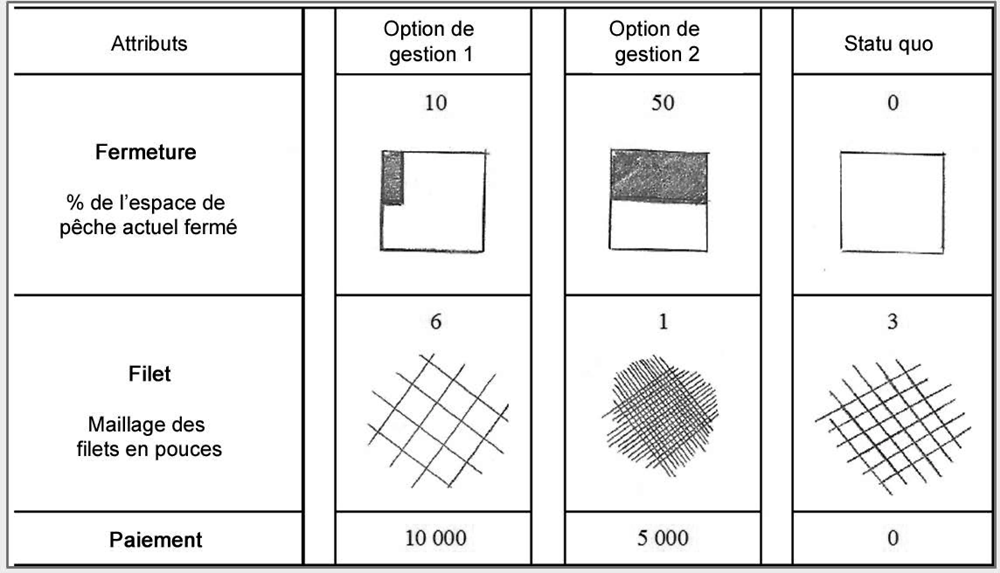
La modélisation de choix multinomial logit est une méthode statistique utilisée pour analyser les choix individuels dans le cadre de décisions complexes. Cette approche permet de comprendre les préférences des individus et d’estimer les probabilités de choix dans un contexte donné. Cependant, cette technique présente également des inconvénients, tels que la nécessité de collecter une grande quantité de données et la restriction aux choix discrets. Il est donc important de peser les avantages et les inconvénients avant d’utiliser cette méthode dans une recherche ou une étude.
Régression logistique binaire dans SPSS avec deux variables prédictives dichotomiques
[arve url=”https://www.youtube.com/embed/iZoaXETWAN4″/]
Pourquoi utiliser un modèle logit ?
Le modèle logit est souvent utilisé dans le contexte des sites de nouvelles pour analyser et prédire le comportement des utilisateurs. Il permet de modéliser une variable binaire, telle que la décision de cliquer sur un article ou de s’abonner à une newsletter. Voici quelques raisons pour lesquelles le modèle logit est préféré :
1. Interprétation des coefficients : Le modèle logit fournit des estimations de coefficients qui permettent d’interpréter l’effet de chaque variable sur la probabilité d’un événement. Cela peut aider les éditeurs de sites de nouvelles à comprendre quels facteurs influencent les comportements des utilisateurs.
2. Flexibilité : Le modèle logit peut être utilisé pour analyser différentes variables indépendantes, telles que l’âge, le sexe, la catégorie d’articles, etc. Il permet également d’inclure des variables continues ou discrètes.
3. Gestion des données manquantes : Le modèle logit gère facilement les données manquantes, car il utilise la méthode des moindres carrés ordinaires pour estimer les coefficients. Cependant, il est important de noter que les résultats peuvent être biaisés si les données manquantes sont liées au résultat.
4. Prédiction : Le modèle logit peut être utilisé pour prédire la probabilité d’un événement en fonction des valeurs des variables indépendantes. Par exemple, il peut être utilisé pour prédire la probabilité qu’un utilisateur clique sur un article en fonction de son âge, de son sexe et de la catégorie d’articles.
En conclusion, le modèle logit est un outil puissant pour analyser les comportements des utilisateurs sur les sites de nouvelles. Il permet d’interpréter les relations entre les variables et de prédire les probabilités des événements, ce qui peut être utile pour prendre des décisions éclairées en matière de contenu et de marketing.
Comment choisir entre Probit et logit ?
Lorsqu’il s’agit de choisir entre Probit et Logit pour le contexte d’un site de nouvelles, il est important de comprendre les différences entre ces deux modèles de régression.
Probit : Le modèle Probit est une méthode de régression qui utilise la distribution normale cumulative pour modéliser la probabilité d’un événement binaire. Il est souvent utilisé lorsque les données présentent une corrélation non linéaire avec les variables explicatives. Par exemple, si vous souhaitez prédire la probabilité de clics sur un article en fonction de différentes caractéristiques telles que l’âge, le sexe, etc., vous pouvez utiliser le modèle Probit.
Logit : Le modèle logit est également une méthode de régression utilisée pour modéliser des variables binaires, mais il utilise la fonction logistique plutôt que la distribution normale. Il est couramment utilisé lorsque l’on souhaite prédire des probabilités dans un contexte où la variable dépendante peut prendre seulement deux valeurs (par exemple, “cliquer” ou “ne pas cliquer” sur un article).
La décision de choisir entre Probit et Logit dépend de plusieurs facteurs, notamment de la nature des données, de l’objectif de la modélisation et des hypothèses qui peuvent être faites. Voici quelques points à considérer :
1. Interprétation des coefficients : Les coefficients obtenus à partir d’un modèle Probit sont plus difficiles à interpréter car ils sont basés sur la dérivée de la fonction normale cumulative. En revanche, les coefficients du modèle Logit sont plus faciles à interpréter car ils sont basés sur la dérivée de la fonction logistique.
2. Hypothèses : Les modèles Probit et Logit reposent sur différentes hypothèses. Le modèle Probit suppose une distribution normale des erreurs, tandis que le modèle Logit suppose une distribution logistique des erreurs. Il est donc important de vérifier si ces hypothèses sont satisfaites dans votre ensemble de données.
3. Performances prédictives : Il peut être utile de comparer les performances prédictives des deux modèles en utilisant des métriques telles que l’AUC-ROC ou la précision. Vous pouvez construire les deux modèles et les évaluer en utilisant des techniques de validation croisée pour déterminer celui qui offre les meilleures performances dans votre contexte spécifique.
En fin de compte, il n’y a pas de réponse définitive quant à savoir quelle méthode est la meilleure. Il est recommandé d’essayer les deux approches et de sélectionner celle qui donne les meilleurs résultats en termes de performance prédictive et d’interprétabilité.
Pourquoi utiliser le modèle probit ?
Le modèle probit est utilisé dans le contexte d’un site de nouvelles pour analyser les préférences ou les comportements des utilisateurs. Il est souvent utilisé pour estimer la probabilité d’un événement binaire, tel que la décision de lire ou non un article ou de cliquer sur un lien.
Le modèle probit est particulièrement adapté dans ce contexte car il permet de prendre en compte des variables explicatives multiples et continues, ainsi que des variables binaires. Par exemple, on peut utiliser des variables telles que l’âge, le sexe, le niveau d’éducation, le temps passé sur le site, etc., pour prédire la probabilité de lecture d’un article.
Le modèle probit est basé sur une fonction de répartition normale standard, appelée la fonction de répartition normale cumulative. Cette fonction attribue une probabilité cumulée à chaque observation en fonction de ses caractéristiques et des coefficients estimés. Ces probabilités cumulées sont ensuite utilisées pour estimer la probabilité individuelle d’un événement.
En utilisant le modèle probit, on peut également estimer les effets marginaux des variables explicatives sur la probabilité d’un événement. Cela permet de quantifier l’impact de chaque variable sur le comportement de l’utilisateur et d’identifier les facteurs les plus influents.
En résumé, le modèle probit est utilisé dans le contexte d’un site de nouvelles pour modéliser et prédire les préférences ou les comportements des utilisateurs en fonction de variables explicatives. Son utilisation permet d’obtenir des informations précieuses sur les facteurs qui influencent les décisions des utilisateurs et d’optimiser les stratégies de contenu.
Quel type de variable à expliquer est utilisé pour un modèle de régression logistique ?
Dans un modèle de régression logistique utilisé sur un site de nouvelles, la variable à expliquer est généralement binaire ou catégorielle. Elle représente la variable que l’on cherche à prédire ou à expliquer en fonction des variables explicatives. Par exemple, on pourrait avoir une variable à expliquer indiquant si un article a été partagé largement ou non.
Dans ce type de modèle, on utilise une variable dépendante ou une variable cible pour représenter la variable à expliquer. Cette variable prend généralement deux valeurs : 0 ou 1 (ou bien une autre catégorie spécifique).
La variable à expliquer est également appelée variable réponse ou variable d’intérêt. Elle peut être représentée par une colonne dans un tableau de données où chaque ligne correspond à une observation (par exemple, un article de presse) et chaque colonne correspond à une variable (par exemple, le nombre de partages).
Il est important de sélectionner judicieusement cette variable à expliquer en fonction de l’objectif de l’analyse. Une bonne définition de la variable à expliquer est essentielle pour obtenir des résultats pertinents dans le modèle de régression logistique.
En conclusion, la modélisation de choix multinomial logit présente à la fois des avantages et des inconvénients. L’un des principaux avantages est sa capacité à prendre en compte un large éventail de variables explicatives pour prédire les choix individuels. Grâce à cette approche, il est possible de comprendre les influences multiples et complexes qui influencent les décisions.
Cependant, cette méthode a également ses limites. Tout d’abord, elle suppose une indépendance des observations, ce qui peut ne pas être réaliste dans certains cas. De plus, la modélisation de choix multinomial logit est sensible aux hypothèses sous-jacentes, telles que l’absence d’hétéroscédasticité et de corrélation croisée entre les alternatives.
En résumé, la modélisation de choix multinomial logit offre une approche puissante pour comprendre et prédire les comportements de choix, mais elle nécessite une attention particulière pour s’assurer que les hypothèses sont respectées et que les résultats sont interprétés correctement. Elle constitue néanmoins un outil précieux pour les chercheurs et les décideurs qui cherchent à étudier les préférences et les comportements des individus.






